I Cut My LLM Costs by 80% With These Token Tricks

If you're building anything that talks to an LLM API, you already know the pain. Every request sends tokens in, gets tokens back, and your bill scales with both. A coding agent that edits files, reads context, and runs commands can burn through millions of tokens in a single session.
I've been building AI-powered products for the last year (including HypeClip, which I sold for 15X ARR), and the single biggest lever on profitability has been reducing LLM token usage. Not switching models. Not negotiating volume discounts. Just sending fewer tokens per request.
These techniques come from studying production codebases (including Claude Code's source) and applying them to my own projects. Every one of them is battle-tested. No theory, no "you could try this." I did try it, and here's what happened.
Patch Edits, Not Full Files
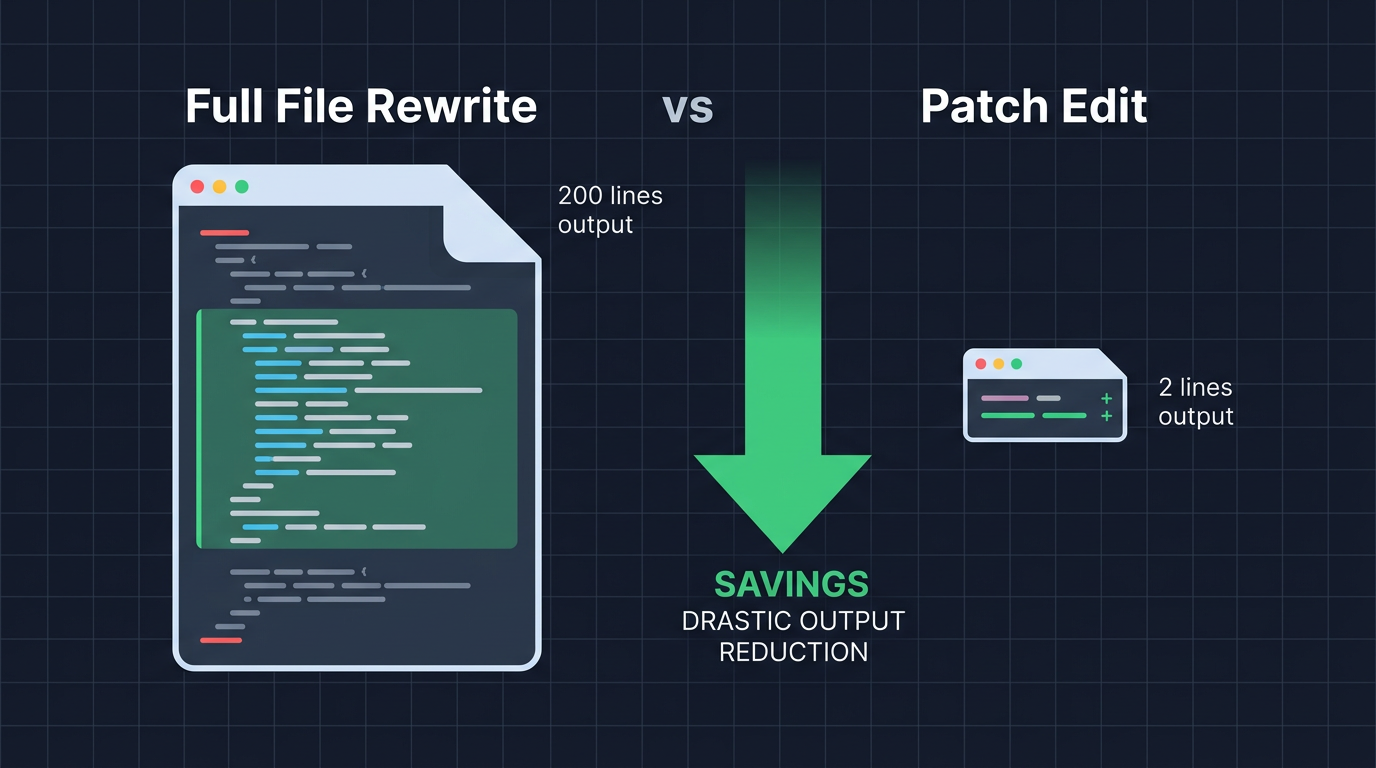
This is the single highest-impact change you can make if your AI agent modifies files.
The naive approach is to send the model a file and ask it to return the entire modified version. A 200-line file with a one-line colour change costs you ~200 lines of output tokens. That's absurd.
The fix is patch-based editing. Instead of outputting the full file, the model specifies only the exact text to find and what to replace it with.
interface PatchEdit {
file: string;
edits: Array<{
old: string; // exact text to find
new: string; // replacement text
}>;
}
That colour change goes from 200 lines of output to 2 lines. The savings are 50 to 95% on every modification task. For a coding agent that edits files dozens of times per session, this compounds fast.
The key prompt instruction is simple: tell the model to use the "minimal unique" old string. Often just 2 to 4 lines of context is enough to locate the edit target uniquely. The smaller the patch, the fewer tokens you burn.
Stop Re-Reading the Same Files
In a multi-turn conversation, your agent will read the same file multiple times. Maybe it reads package.json at the start, edits something else, then reads package.json again to check a dependency. Each read dumps the full file contents into the context window.
The fix is a file read cache keyed on path and modification time. If the file hasn't changed since the last read, return a one-line stub instead of the full contents.
const readCache = new Map<string, { mtime: number; content: string }>();
function readFile(path: string): string {
const stat = fs.statSync(path);
const cached = readCache.get(path);
if (cached && cached.mtime === stat.mtimeMs) {
return "[File unchanged since last read]";
}
const content = fs.readFileSync(path, "utf-8");
readCache.set(path, { mtime: stat.mtimeMs, content });
return content;
}
A 500-line file read twice goes from ~1,000 lines in context to ~500 lines plus a one-line stub. The model already has the content from the first read, so it loses nothing. You just stop paying for the duplicate.
Cap Everything
Shell commands, search results, and file reads can produce enormous output. A grep across a monorepo might match 10,000 lines. An npm install might dump 500 lines of dependency resolution. If you send all of that to the model, you're paying for tokens that the model will never meaningfully use.
Set hard caps on every tool output:
- Shell output: 30,000 characters (truncate the middle, keep head and tail)
- Search results: 250 matches max, paginated so the model can fetch more if needed
- File reads: 2,000 lines max
- Grep line width: 500 characters per line
When output is truncated, always tell the model how much was cut. This is critical. If the model knows "450 lines were truncated," it can decide to narrow its search or paginate. If it doesn't know, it assumes it has everything and makes bad decisions.
function capOutput(output: string, limit: number): string {
if (output.length <= limit) return output;
const truncated = output.slice(0, limit);
const remaining = output.length - limit;
return `${truncated}\n\n... [${remaining} characters truncated] ...`;
}
The same principle applies to aggregate budgets. When tools run in parallel, each might produce large output independently. Five parallel tool results at 30K characters each is 150K characters in a single message. Set a per-message budget (say 50K total) and persist the largest results to disk, replacing them with short previews. Five 30K results become five 2K previews. That's 150K down to 10K.
The Compaction Pipeline

Every long conversation eventually hits the context window limit. You need to compress history before that happens. The naive approach is to call the LLM to summarise the conversation. But that summarisation call itself costs tokens. Lots of them.
The smarter approach is tiered compaction. Run the cheapest operations first. Only call the LLM if you still need space.
- Enforce tool result budgets (free). Persist large tool results to disk, replace with previews.
- Snip old messages (free). Drop messages beyond a turn threshold that are unlikely to be referenced again.
- Microcompact (free). Clear old tool results from specific tools (file reads, shell output, search results) and replace them with a one-line placeholder. A file you read 15 turns ago is almost certainly stale.
- Context collapse (free). Collapse staged sections that are no longer needed.
- Full LLM summarisation (expensive). Only if the free tiers didn't free enough space.
The order matters. Each tier tracks how many tokens it freed. If microcompact alone frees 40K tokens, the expensive summarisation call never fires. In my experience, tiers 1 through 3 handle about 70% of compaction events without ever touching the LLM.
When you do run the full summarisation, structure the output. Ask for specific sections: user goal, changes made, current state, issues, next steps. Strip any reasoning/drafting the model did during summarisation (let it think in <analysis> tags, then delete those tags from the stored summary). You get better quality summaries and a tighter result.
The principle: cheapest operations first. Free token savings always beat LLM-powered token savings.
Prompt Caching
With Anthropic's API, cached input tokens cost 90% less than fresh input tokens. If you're not optimising for cache hits, you're leaving money on the table.
The core rule is simple: every byte before your cache breakpoint must be identical across requests. If anything changes in the cached prefix, the entire cache is busted and you pay full price.
Three practical techniques make this work:
Split your system prompt into static and dynamic sections. Your identity, rules, tool descriptions, and tone guidance are static. They never change between requests. Your session context, user state, and MCP server info are dynamic. Put a boundary marker between them. Everything before the marker gets cached globally. Everything after it doesn't.
Sort your tools deterministically. Tools are part of the API request payload. If their order changes between requests (because you added an MCP tool, or your array ordering is nondeterministic), the serialised payload changes and the cache is busted. Sort built-in tools alphabetically as a prefix, MCP tools alphabetically as a suffix. Now adding or removing an MCP tool only changes the suffix.
Freeze your replacement strings. When you replace a tool result with a preview or summary (via the compaction pipeline above), the replacement must be byte-identical on every subsequent request. If the replacement text varies even slightly, the cached prefix is invalidated. Store the replacement string alongside the decision and replay it exactly.
const replacementCache = new Map<string, string>();
function getOrCreateReplacement(id: string, content: string): string {
if (replacementCache.has(id)) {
return replacementCache.get(id)!;
}
const replacement = content.slice(0, 2000) + "\n[truncated]";
replacementCache.set(id, replacement);
return replacement;
}
Getting prompt caching right turned a 10% cache hit rate into a 90%+ hit rate in my projects. At scale, that's the difference between a viable product and an unprofitable one.
Use the Right Model
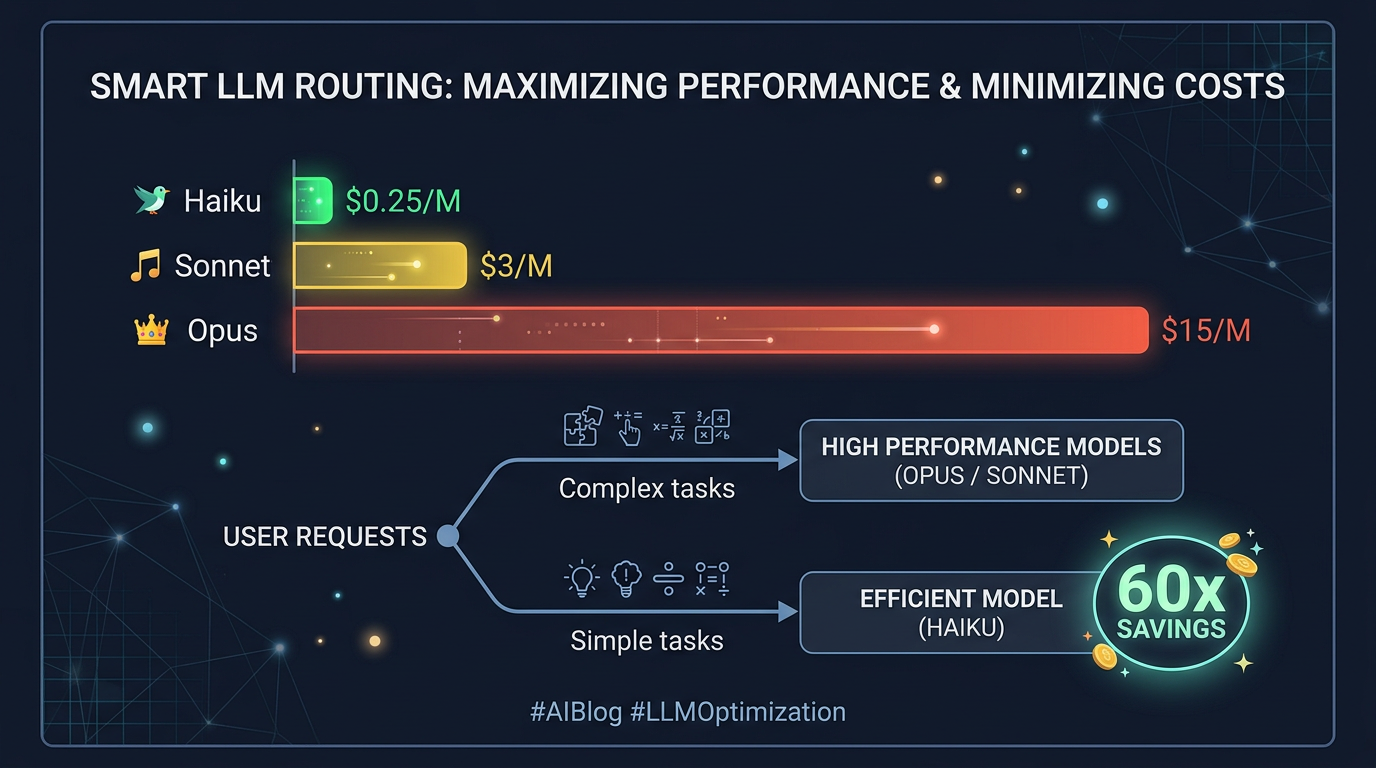
Not every LLM call needs your most powerful (and most expensive) model. A classification task, a summary, a quota check, or a status label doesn't need Opus-level reasoning. It needs a fast, cheap answer.
The cost differences are dramatic:
- Haiku: ~$0.25 per million input tokens
- Sonnet: ~$3 per million input tokens
- Opus: ~$15 per million input tokens
That's a 60x cost difference between Haiku and Opus. If 40% of your LLM calls are auxiliary tasks (and in most agent architectures, they are), routing those to Haiku cuts your total spend significantly.
Here's how I think about routing:
- Main generation loop (code writing, complex reasoning): Use your best model. This is where quality matters.
- Classification and yes/no decisions: Haiku. Set
maxTokensto 5. It only needs one word. - Summarisation for compaction: Haiku or the same model (same model if you want cache sharing with the main conversation).
- Tool result labels and status checks: Haiku. A 30-character label doesn't need a $15/M model.
const MODELS = {
primary: "claude-sonnet-4",
auxiliary: "claude-3.5-haiku",
};
async function classify(input: string): Promise<boolean> {
const result = await llm.generate({
model: MODELS.auxiliary,
maxTokens: 5,
temperature: 0,
messages: [{ role: "user", content: `Valid request? YES/NO: ${input}` }],
});
return result.startsWith("YES");
}
The same principle applies to thinking budgets. Extended thinking (chain-of-thought) can burn 10K+ reasoning tokens before the model even starts its response. For complex architecture decisions, that's worth it. For "add a comment to this function," it's pure waste. Match the effort to the task.
Prompt Engineering for Free Savings
Some of the biggest wins require zero code changes. They're just better prompts.
Set explicit length constraints. Without guidance, models are verbose. They explain what they're about to do, summarise what they did, add disclaimers. Tell the model exactly how concise to be: "Between tool calls, max 1 to 2 sentences. Final response, max 3 to 4 sentences unless the user asked for detail."
Use relative paths, not absolute paths. /Users/nick/WebstormProjects/my-project/src/components/Button.tsx uses far more tokens than src/components/Button.tsx. Relativise all paths in tool results and prompts.
Use transcript pointers instead of verbatim history. After compaction, instead of stuffing pre-compaction details into the summary, point to the transcript file. "For full conversation history, read: /path/to/transcript.txt." The model can read it on demand if needed, but usually doesn't.
Suppress post-compaction chatter. After any context reset, add: "Continue from where you left off. Do not summarise what happened. Do not ask what to do next. Just resume the task." This prevents the model from wasting output tokens on meta-commentary.
Each of these is trivial to implement. Together, they compound into 30 to 50% output token reduction.
What This Means in Practice
When I was running HypeClip's AI pipeline on a $350/month AWS bill, every dollar of unnecessary LLM spend ate directly into margins. The same is true for any indie hacker building products on the side. You don't have enterprise budgets. You have a credit card and a Stripe account.
Applying these techniques across my projects reduced total LLM costs by roughly 80%. The breakdown:
- Patch edits and file dedup saved ~40% on a per-session basis
- Prompt caching (once optimised) cut billed input tokens by ~60%
- Model routing saved another 30 to 40% on auxiliary calls
- Tiered compaction kept long sessions alive without expensive summarisation calls
The honest takeaway: most of the savings come from a small number of high-impact changes. Patch edits, prompt caching, and model routing are the big three. Everything else is refinement.
Measure first. Track token usage per turn, cache hit rates, and cost per task. Find your biggest line item and optimise that. Not the most interesting technique, not the cleverest trick. The one that's actually costing you money.

Nick Morgan
Technology Director by day, indie hacker by night. I write about building products, validating ideas, and shipping fast. Subscribe for indie hacking tips and tricks, delivered monthly.


